Blog
Why AI code fails differently
What I learned talking to 200 engineering teams
Paul Sanglé-Ferrière
Nov 12, 2025
I talked to an engineering team last week. They'd shipped an AI-generated PR that took down their checkout flow. Tests passed. CI was green. Code review looked fine.
AI had "optimized" their payment processing:
Looks reasonable. The analytics service has a 2-second timeout. When it's slow, payment processing times out. Integration tests passed because the mocked analytics service responds instantly. E2E tests in staging passed because analytics had spare capacity.
In production, under real load, 95th percentile latency went from 200ms to 8 seconds. Revenue dropped 15% before they caught it.
Three hours of downtime. $50k in lost revenue. And they had no idea how to prevent it from happening again.
The pattern I started seeing everywhere
After hearing stories like this, I started talking to more engineering teams. 200+ conversations later, a pattern emerged.
Some teams were shipping 10-15 AI PRs daily without issues. Others had tried once, broken production, and given up on AI entirely.
The difference wasn't model choice or prompt engineering. It was something else entirely.
Semantic violations vs syntax errors
Traditional CI/CD catches syntax errors, type mismatches, and test failures. Human mistakes - typos, off-by-one errors, forgotten edge cases. We've spent decades perfecting tools for these.
AI makes different mistakes. It generates syntactically perfect code that violates your system's unwritten rules.
Everyone on that team knew you queue analytics events asynchronously. But that wasn't documented anywhere. It's just something they learned when analytics had an outage in 2022.
The obvious objection: "Just write better tests."
You could write a specific test for "analytics calls must be queued" but you'd need to know that rule exists first. The problem is discovering and encoding these rules systematically.
Another team had a similar issue: AI changed a private auth method to public, exposing an internal method that bypassed security checks. Auth integration tests should catch this. But without tests specifically checking "this method must remain private," it slipped through.
The institutional knowledge problem
Every codebase has landmines:
That
cache.Clear()cascades and deletes 50GBThe user service MUST be called before the auth service (backwards, yes, but fixing it now would require migrating 50 services)
Never import utils into models (circular dependency nightmare from 2020)
Never query the users table in a loop (brought down prod for 3 hours in 2021)
The legacy billing service crashes on requests over 1MB
This is institutional knowledge. It lives in engineers' heads, accumulated through incidents and 3am debugging sessions.
AI optimizes for general correctness, not your specific constraints. It sees that auth bypasses and thinks "unused private method" and makes it public. It sees sequential calls and thinks "these could run in parallel" without knowing about the ordering dependency.
The code looks better. Often it IS better in a general sense. But it's wrong for your system.
Natural language rules
The teams successfully using AI had converged on the same approach: write constraints in plain English that AI enforces.
Real examples:
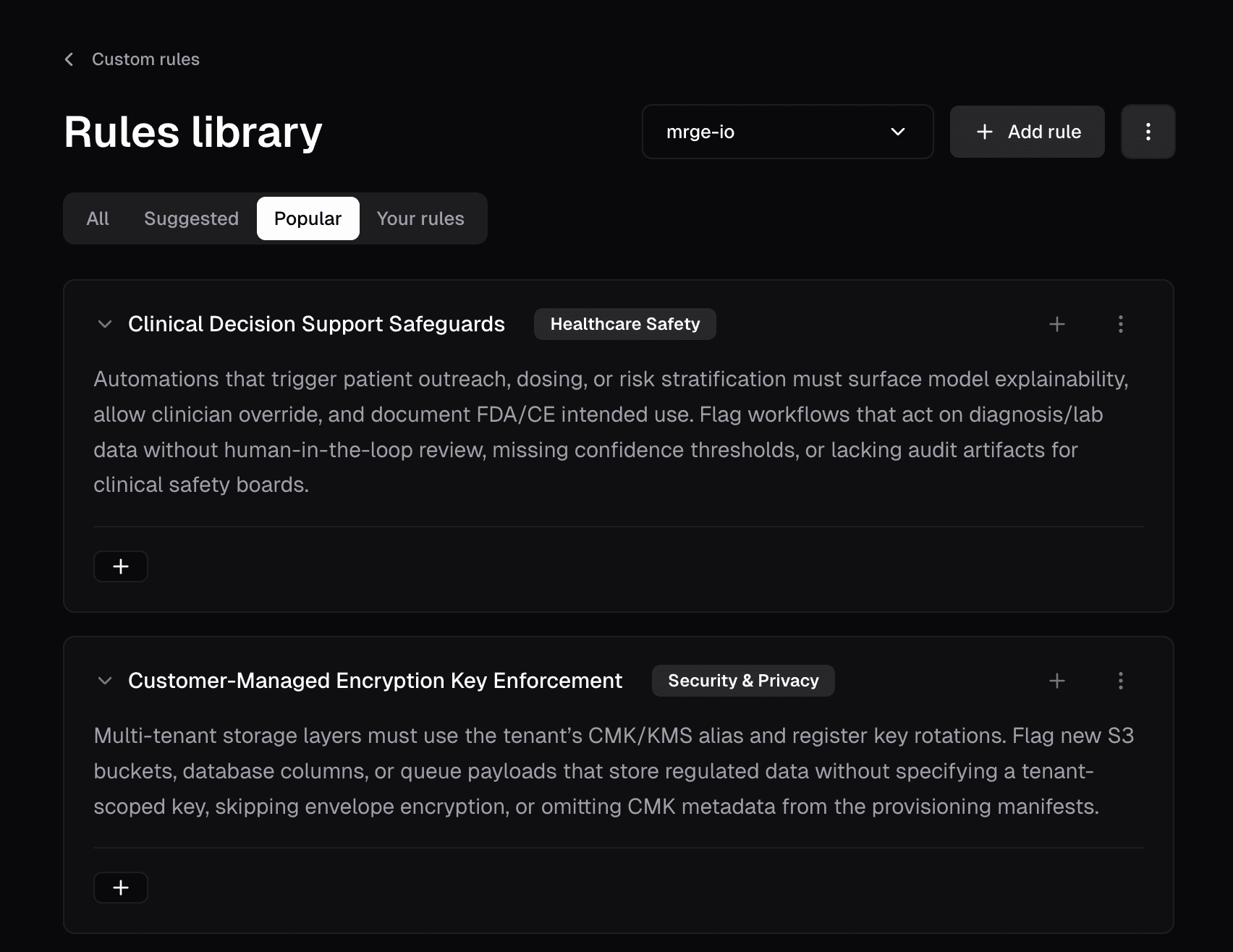
The obvious question: "How is this different from code comments?"
These are enforced, not documented. AI scans every PR. If code violates a rule, it blocks the merge and explains why:
"This queries the users table inside a loop. This pattern caused a 3-hour outage in 2021 (incident #247). Consider batch loading with a WHERE IN clause or using a JOIN."
The tricky part is implementation. The naive approach - regex or AST pattern matching - breaks immediately. "Don't call analytics synchronously from API endpoints" means understanding that ServiceWrapper.execute() eventually calls analytics three layers deep through a factory pattern.
You need semantic understanding of the entire call graph, not just pattern matching.
One of the teams we work with has a rule about descriptive naming in auth code:
The system reads the code, understands which package it's in, and applies the rule contextually. userId in components/UserProfile.tsx is fine. userId in middleware/auth.ts gets flagged.
Not regex. Semantic understanding of what the code does and where it lives in your architecture.
AI code review tools are misguided
Most AI code review tools look for bugs - null pointer exceptions, race conditions, memory leaks. These are the same problems linters and static analyzers catch.
That's not what kills you with AI code.
What kills you is AI violating rules that exist only in your team's collective memory. The constraint about service call ordering. The performance requirement that isn't written down. The architectural boundary that everyone respects but no one documented.
Bugs are easy. Institutional knowledge violations are what break production.
What we learned
When you're shipping 10x more code, validation becomes the bottleneck. Not generation speed or model quality - making sure code won't cause unintended side effects.
Three things that actually work:
1. Start with your last five incidents
Each one becomes a rule. "Don't do X because it caused incident #Y." Most teams can prevent 80% of potential AI issues by encoding their 20 most painful lessons.
2. Disagreement is signal
When your AI code generator and AI validator disagree, route it to senior engineers. These are learning opportunities - places where the code looks normal but doesn't match your patterns.
3. Preview environments catch what rules miss
Spin up every PR in its own environment. Let someone click through it. You'll catch that auth bypass when someone tries logging in, not after deploying to prod.
Where this is going
The teams shipping AI at scale aren't waiting for better models. They're building better validation.
Everyone else is optimizing the wrong thing. Generating more code faster doesn't help if you can't safely ship it. The bottleneck isn't generation - it's validating that generated code won't break your specific system in ways only your team knows about.
That's why we built cubic - the best automated code review tool. Natural language rules, semantic validation, automated enforcement. It's working for Better Auth, n8n, Cal.com, and about 50 other teams now.
But the approach matters more than the tool. You can start with a simple document listing constraints. The key insight is recognizing that AI needs explicit access to your team's implicit knowledge.
The future isn't about prompting AI to write better code. It's about systematically encoding the constraints that make code correct for YOUR system. Teams that figure this out first are building a durable advantage. Every rule written, every pattern identified, every constraint encoded - it compounds.
The gap between "AI that generates code" and "AI you can trust in production" isn't about model capabilities. It's about bridging the institutional knowledge gap.
That's the actual problem.
